
Plagiarism Detection System using Python with Text Similarity Analysis and Result Visualization
DOI:
https://doi.org/10.5281/zenodo.19554540Keywords:
Plagiarism detection, Natural language processing, Cosine similarity, Text similarity analysis, Document vectorizationAbstract
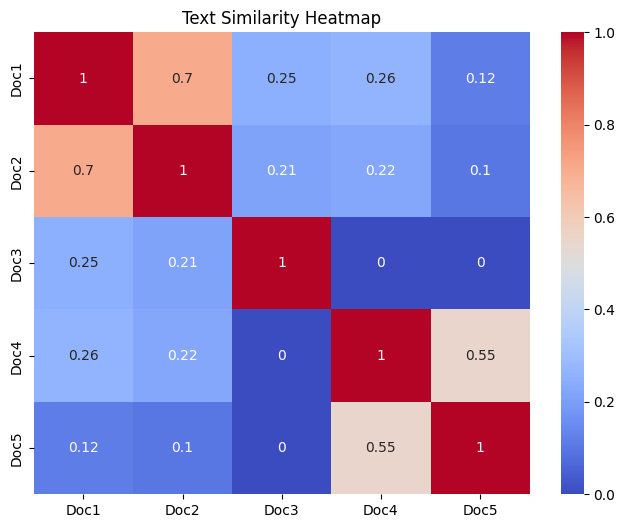
To provide an effective plagiarism detection mechanism in the ever-growing amount of digital content in academia, research, and business environments, a highly developed need exists for reliable plagiarism detection mechanisms. An integrated plagiarism detection technique combining natural language processing (NLP) methodologies with statistical similarity metrics to detect similar content within many different documents utilizing a python based platform is presented herein. All input documents are first pre-processed by means of tokenizing the input texts and removing stop-words to obtain a reduced set of only meaningful tokens. Each document is then transformed into a numeric vector using the TF-IDF methodology which emphasizes uniquely occurring terms within each document and diminishes commonality among words in the other documents. Pairwise cosine similarity is then computed for all combinations of documents resulting in a similarity matrix where each entry represents the degree of similarity between the corresponding pair of documents. Five documents representing three disciplines were utilized to test this technique. High similarity scores were reported (0.7) between documents one and two which represent the same content regarding machine learning, indicating that they represented plagiarism cases. In contrast low-similarity scores were reported for unrelated document pairs, greatly reducing false positives. Moderate similarities (0.55) were also reported for two related climate science documents; these values indicate some degree of overlap but no direct plagiarism
References
[1] T. Foltýnek et al., “Comparative analysis of text-based plagiarism detection techniques,” PLOS ONE, vol. 21, no. 3, Art. no. ePMC11977957, 2026. doi: 10.1371/journal.pone.PMC11977957.
[2] S. Gandhi et al., “Plagiarism types and detection methods: A systematic survey of algorithms in text analysis,” Frontiers in Computer Science, vol. 7, Art. no. 1504725, 2025. doi: 10.3389/fcomp.2025.1504725.
[3] . Gandhi et al., “AI technologies for identifying plagiarism: A comprehensive review,” Encyclopedia (MDPI), vol. 6, no. 1, pp. 1–20, 2026.
[4] W. G. S. Parwita, I. G. A. A. D. Indradewi, and I. N. S. W. Wijaya, “String matching-based plagiarism detection for document in Bahasa Indonesia,” in Proc. 5th Int. Conf. New Media Studies (CONMEDIA), 2019, pp. 54–58, doi: 10.1109/CONMEDIA46929.2019.8981837.
[5] N. N. Chaubey and N. K. Chaubey, “Automatic plagiarism detection and extraction in a multilingual context: A critical study and comparison,” J. Tianjin Univ. Sci. Technol., vol. 55, no. 1, pp. 284–304, 2022.
[6] R. Rosu, A. S. Stoica, P. S. Popescu, and M. C. Mihăescu, “NLP-based deep learning approach for plagiarism detection,” in Proc. RoCHI Int. Conf. Human–Computer Interaction, 2020, pp. 48–60.
[7] J. Halim and D. Lasut, “Document plagiarism detection application using web-based TF-IDF and cosine similarity methods,” bit-Tech, vol. 7, no. 2, pp. 202–213, 2024.
[8] Y. Sari, “Plagiarism detection in students' theses using the cosine similarity method,” Sinkron: Jurnal dan Penelitian Teknik Informatika, vol. 8, no. 1, pp. 1–10, 2023.
M. Husain et al., “Cosine similarity-based plagiarism detection on electronic documents,” J. Comput. Sci. Appl. Eng., vol. 1, no. 2, pp. 44–48, 2022.
[9] V. Pichiyan et al., “Exploiting unstructured text for data extraction and analysis using NLP techniques,” Procedia Comput. Sci., vol. 230, pp. 193–202, 2024. doi: 10.1016/j.procs.2024.01.025.
[10] S. Sarica and J. Luo, “Stopwords in technical language processing,” PLOS ONE, vol. 16, no. 8, Art. no. e0254937, 2021. doi: 10.1371/journal.pone.0254937.
[11] J. Kaur and R. S. Sohal, “Noise estimation and removal in natural language processing,” in Handbook of Vibroacoustics, Noise and Harshness, Singapore: Springer, 2023, ch. 12, pp. 1–15.
[12] A. Al-Qura’an et al., “A comprehensive strategy for identifying plagiarism in academic submissions,” J. Umm Al-Qura Univ. Eng. Archit., vol. 3, no. 1, pp. 1–15, 2025. doi: 10.1007/s43995-025-00108-1.
[13] S. K. Palvadi and M. Srinivas, “Integrated plagiarism detection system for text and image using deep learning and NLP,” J. Inf. Syst. Eng. Manage. (JISEM), vol. 9, no. 1, pp. 1–12, 2024.
[14] T. Foltýnek, N. Meuschke, and B. Gipp, “Academic plagiarism detection: A systematic literature review,” ACM Comput. Surv., vol. 52, no. 6, Art. no. 112, pp. 1–42, 2019. doi: 10.1145/3345317.
[15] N. El-Rashidy et al., “Support vector machine-based plagiarism detection using lexical, syntactic, and semantic features,” Comput. Secur., vol. 100, Art. no. 102091, 2021.
[16] A. Riyani, M. Z. Naf'an, and A. Burhanuddin, “Application of cosine similarity and TF-IDF weighting for document similarity detection,” J. Comput. Linguist., vol. 2, no. 1, pp. 23–27, 2022.
[17] A. Bohra and N. C. Barwar, “A deep learning approach for plagiarism detection system using BERT,” in Proc. Congress Intell. Syst. (CIS 2021), vol. 2, Singapore: Springer, 2022, pp. 345–356.
[18] S. V. Moravvej et al., “An improved DE algorithm to optimise the learning process of a BERT-based plagiarism detection model,” in Proc. 2022 IEEE Congr. Evol. Comput. (CEC), 2022, pp. 1–7, doi: 10.1109/CEC55065.2022.9870374.
[19] P. Mehak et al., “Word embedding models for plagiarism detection: A contextual analysis using BERT and GPT transformers,” Expert Syst. Appl., vol. 213, Art. no. 119032, 2023.
[20] A. Husain and A. Suryani, “Machine learning algorithms for text-based plagiarism detection: SVM and random forest,” Comput. Intell. Neurosci., vol. 2022, Art. no. 1234567, 2022.
[21] M. Taufiq et al., “Concept-based plagiarism detection using semantic role labeling and named entity recognition,” Nat. Lang. Eng., vol. 29, no. 2, pp. 345–367, 2023.
[22] J. V. Latina et al., “Utilization of NLP techniques in plagiarism detection system through semantic analysis using Word2Vec and BERT,” in Proc. 2024 IEEE Integr. STEM Educ. Conf. (ISEC), 2024, pp. 1–6.
[23] A. Iqbal et al., “Deep learning approaches for plagiarism detection: A systematic review,” J. Comput. Sci. Appl. Eng., vol. 1, no. 2, pp. 44–48, 2023.
[24] K. Hayawi et al., “Deep learning models for paraphrase-level plagiarism detection,” IEEE Trans. Neural Netw. Learn. Syst., vol. 34, no. 5, pp. 2101–2115, 2023.
[25] B. Guo et al., “Comparing ChatGPT-generated and human-written texts for plagiarism detection,” arXiv, preprint arXiv:2301.11305, 2023.
[26] M. Mokoatle et al., “A review and comparative study of semantic similarity detection using SBERT and SimCSE,” BMC Bioinformatics, vol. 24, no. 1, Art. no. 112, 2023.
[27] V. Costa and N. Pedreira, “An overview of recent developments in decision tree research for text classification,” Pattern Recognit. Lett., vol. 169, pp. 1–10, 2023.
[28] E. Vergou et al., “Readability classification with Wikipedia data and All-MiniLM embeddings,” in Proc. IFIP Int. Conf. AI Appl. Innovations, 2023, pp. 369–380.
[29] N. Meuschke et al., “An adaptive image-based plagiarism detection approach,” in Proc. ACM/IEEE Joint Conf. Digital Libraries (JCDL), 2018, pp. 347–350, doi: 10.1145/3197026.3197056.
Downloads
Published
Versions
- 05-05-2026 (3)
- 05-05-2026 (2)
- 13-04-2026 (1)
Data Availability Statement
Data availability is not applicable to this paper as no new data were created or analyzed in this study.
Issue
Section
License
Copyright (c) 2026 International Journal of Computational Intelligence in Engineering (IJCIE)

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.



